Today I'm releasing a big patch release (v1.1.5) for elm-review-unused, elm-review's main package to detect and remove unused code from Elm code.
I wrote previously about how elm-review and this package are so good at detecting and removing dead code, and I hinted at some of the changes included in this release. Let's get into it.
Detection of custom type constructors that will never be used
NoUnused.CustomTypeConstructors has become quite a bit smarter. In the example below, it will detect that Unused is in fact unused.
type SomeType
= Used
| Unused
defaultValue : SomeType
defaultValue = Used
doSomething : SomeType -> ( SomeType, SomeType )
doSomething value =
case value of
Used -> ( Used, Used )
Unused -> ( Unused, Used )
toString : SomeType -> String
toString value =
case value of
Used -> "used"
Unused -> "unused"Why can it be considered unused? NoUnused.CustomTypeConstructors reports custom type constructors that are never used (while ignoring references to those in pattern match patterns).
So in the following more simplified example, since we never ever construct Unused anywhere, we can remove it and its handling in the case expression.
type SomeType
= Used
| Unused -- line can be removed
defaultValue = Used
toString : SomeType -> String
toString value =
case value of
Used -> "used"
Unused -> "unused" -- line can be removedThen what about the first example? There is definitely a reference to Unused in case value of Unused -> ( Unused, Used ).
What you may notice is that to create an Unused value, you actually need value to have that same value, so you need Unused to be constructed somewhere else in the project. If that never happens, then there is no way we can ever enter this pattern, which in turn means we'll never be able to construct an Unused value.
I'll try to make it even smarter in the future to handle even more cases!
Ignore custom type constructors in comparisons
Similarly to above, we now ignore custom type constructors that are used in comparisons.
b = if a == Unused then ... else ...Here, even though Unused is "constructed", it won't count towards marking the constructor as used, since it only serves as checking if the value is of that type.
If we find out Unused is never used anywhere else, we can remove it and change the condition to always be True (when using /=) or False (==).
The constructor is still counted when you do things like a == fn Unused though.
In the future, I would like to be able to tell that we can ignore any mentions of Unused in the branch that requires having an Unused already constructed.
Special casing types aimed to be used as phantom types
I have already written about phantom types but basically it's when you have a custom type with a type variable but that type variable never appears in its variants.
It is mostly used to prevent mixing data that is under the hood implemented the same way, and a common example is this one:
type Currency a = Currency Int
type Euro = Euro
type Dollar = Dollar
twoEuros : Currency Euro
twoEuros =
Currency 2
twoDollars : Currency Dollar
twoDollars =
Currency 2
-- Compiler error: these are two different types
twoDollars == twoEurosOne problem is that the rule NoUnused.CustomTypeConstructors would look at the Currency constructor and think that it is unused.
Thankfully (and with quite some work), the rule has always been smart enough to figure out whether the type was used in the stead of a phantom type variable. Though the knowledge of what type variable is "phantom" or not gets lost with types coming from dependencies (but you can inform the rule, that is why the rule takes some optional configuration).
Anyway, these types like Euro and Dollar are not really meant to be used. They are mostly there only to be used with Currency. If I saw this something like a = Euro, I'd find it a code smell and I'd investigate.
Martin Stewart showed me that it's fairly easy to prevent that from occurring in the code, and to make sure that a type is only used for phantom types: just add Never.
type Euro = Euro Never
type Dollar = Dollar NeverSo long story (mostly because I wanted to give the tip) short: Whenever NoUnused.CustomTypeConstructors sees this it won't report the constructor. The type itself will still be reported by NoUnused.Variables though, no worries.
Recursive let functions
We usually detect unused functions by counting how many times they are referenced. If the count is 0, then we consider it unused. Recursive functions reference themselves (by definition), meaning that to notice when one such function is unused, there needs to be some special handling.
NoUnused.Variables already reported recursive functions which are never called elsewhere, but we didn't do this for functions defined in a let expression.
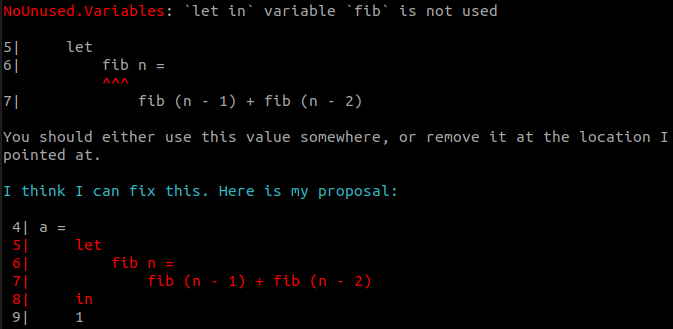
A next step in this direction would be to detect unused indirectly-recursive functions. Things like a calling b calling a where neither is referenced elsewhere. That would be a bit trickier to keep track of, but it's definitely do-able!
Recursive custom types
Similarly, NoUnused.Variables now also reports unused custom types that reference themselves such as this one:
type Node =
Node Int (List (Node))Better handling of imports
The NoUnused.Variables now looks at the contents of other files, which makes it much smarter about what is really happening with imports. This has an impact on plenty of situations:
Removing imports does not provide a lot of value, it is mostly a "cosmetic" thing. That said, it will help detect unused dependencies, and help you avoid potentially unnecessary import cycle errors.
Side-note on that: elm-review now reports more accurate import cycles than the compiler (see the announcement thread). I have provided feedback so that my learnings can be incorporated into the compiler in the future.
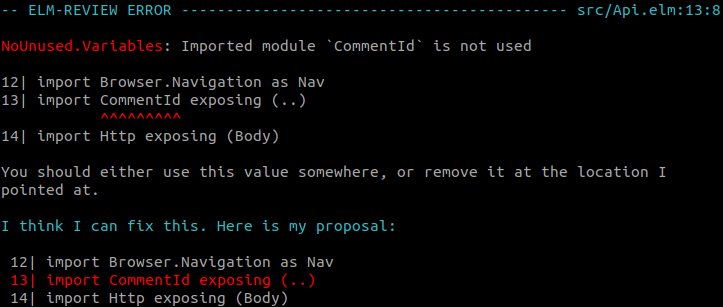
Unused imports that import everything
This one has been a thorn in my side for such a long time, especially since some IDE plugins for Elm would tell you about them already.
Unused type imports that expose the constructor
Similarly, we were not reporting the importing of a custom type and its constructors even when that was possible.
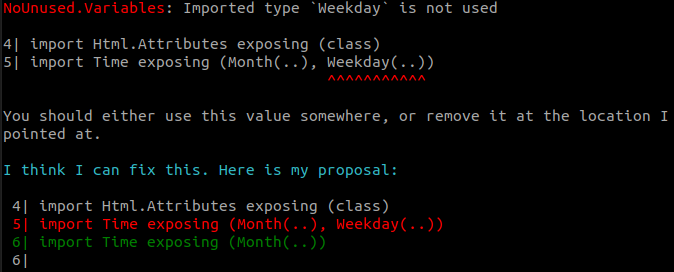
If in the example above, the type Weekday was used in a type annotation but its constructors were not, then the proposed fix would be to only remove the (..).
Shadowing imported elements
Elm famously doesn't allow shadowing variables. Except that it does, when you override something that was imported from another module.
That makes somewhat sense because you don't want code like the following to not compile because text was implicitly imported from Html.
import Html exposing (..)
import Module exposing (toUpper)
updateText comment text = -- "text" overrides the reference to "Html.text"
{ comment | text = toUpper text }
toUpper = -- Overrides the reference to "Module.toUpper"
String.toUpperThe imported toUpper also gets ignored by Elm. Maybe it could be reported by the compiler, but at the moment it will just become an unusable reference.
We were previously not reporting two kinds of problems due to not handling this shadowing well enough. The first one is when you define a variable (not at the top-level) named like an imported element.
import Html exposing (id)
something value =
case value of
SomeValue id -> -- this id is not used here
model + 1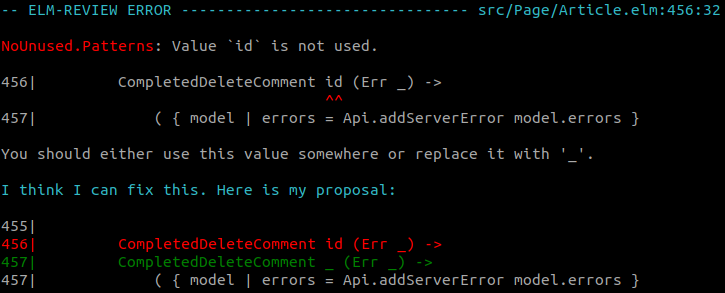
This is especially confusing because id can refer to different things even in the same function.
The second kind of problem is when you define a top-level variable or type which was also being imported, be it a type or a function.
import Article.Body exposing (Body)
type ValidatedField
= Title
| Body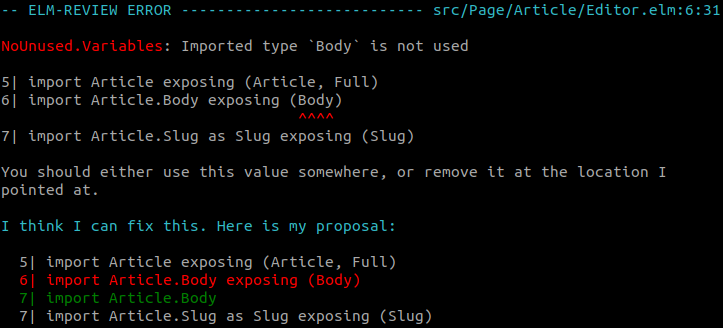
I find this one to be very scary. If we take the example of toUpper above, removing the top-level declaration toUpper declaration will at best lead to a compiler error, and at worst, when the types are the same, a non-obvious change in the logic. So it's best to remove these early on while the problem hasn't shown up yet!
Shared names for imports
NoUnused.Variables can now detect unused imports, even when different modules are imported with the same name or alias.
module A exposing (a)
import List
import SomeModule as List -- is unused
a = List.singleton 1Pattern matches
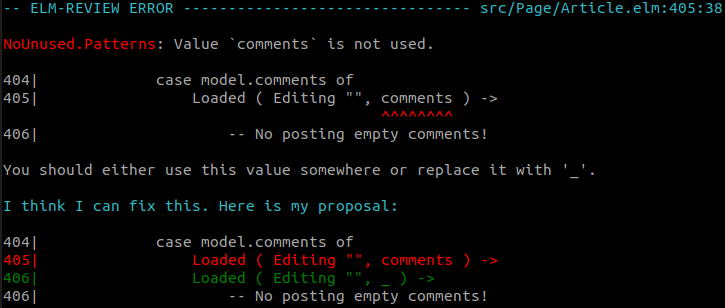
NoUnused.Patterns reports unused variables extracted in patterns (think case expressions). It had a bug where a variable would be considered used if another one with the same name was used somewhere else.
case model.comments of
( Editing str, comments ) ->
-- comments is used here
str :: comments
( Editing "", comments ) ->
-- comments is not used here, but we weren't reporting
[]
Wildcard assignments
Let declarations assigned to _ will now be reported and removed.
a =
let
_ = value
in
1
-- becomes
a =
1Smaller changes
- False positive fix: Types in let declaration type annotations are now considered used.
- The
mainfunction will now be reported if the project is a package. - Unused infix operator declarations will now be removed (just in case the core team wants to start using
elm-review) - There is now a fix for the import of unused operators.
And some more I may have forgotten!
Afterword
You can try elm-review with these rules by running:
npx elm-review --template jfmengels/elm-review-unused/example
# Then if you want to adopt it, use `init`
npx elm-review init --template jfmengels/elm-review-unused/exampleMost of these changes are relatively small changes which will detect rare cases or report things with I think little value compared to what was already being checked.
That said, and as I mentioned in Safe dead code removal in a pure functional language, sometimes it's these little changes that can end up leading to the discovery of bigger swathes of unused code. Also it may help prevent unnecessary import cycle issues.
I now believe that elm-review is the best tool out there to detect unused code and help you remove it. I don't believe that there is a tool out there that can remove Elm code that this one isn't able to*. If you do find unused code somewhere that is not being reported, please open an issue!
* Possible exception for elm-xref in some specific use-cases, like the indirectly-recursive functions.
Please report any bugs that you may find, and please let me know how much dead code these changes helped uncover! (via Twitter or on #elm-review in the Elm Slack).